Introduction
A few weeks ago, I saw a thread about a convention/hackathon in Madrid about AI. I was on the bus with 3% battery left, and I said "why not," without expecting much from it or putting much effort into my submission. A few days later, I got invited alongside 44 other people, out of 360+ submissions, to participate in REFUGIO's hackathon: a 4-hour competition with 15 teams of 3. Shortly after, I booked my stay in Madrid.
The day before the event, we got a preview of every member who would attend: a picture of them alongside a small description. And wow... saying that I felt small would be an understatement. There were so many smart people from so many different areas: engineering, astrophysics, medicine, and, of course, machine learning and artificial intelligence. How did I get here?
Not much later, we also got more information about the hackathon. We didn't know what the challenge would be yet, but we knew that it'd be a A competition format where teams submit solutions and are ranked by score on a shared leaderboard., and we also got to know who our teammates would be. I got paired with Alejandro, a A field that applies computational methods to chemical and molecular data. PhD researcher working with AI and big data, and Alfonso, an industrial & power systems engineer. Both amazing teammates and great people, but more on that later.
2 Hours Until Hour 0
After all of the participants arrived, two speakers joined us to give talks about what they were doing in their own work and how they were using AI. They came from two small companies, NVIDIA and Microsoft, pretty unknown so I can't blame you if you don't recognize them... /s
First, Guillermo Garcia Cobo, an Machine learning: AI systems that learn patterns from data instead of being programmed with every rule directly. engineer currently focusing on and building AI systems designed to perceive, plan, and act in the physical world, such as robots or autonomous vehicles.. More specifically, autonomous driving, like Tesla and Waymo. He talked us through the process they followed at NVIDIA in collaboration with Mercedes, what they did and why they did it. Also mentioned was OmniDreams, a real-time generative world model specifically made for autonomous vehicle simulation, which is one of the tools they used and are currently using to obtain fully autonomous driving through AI. Despite me having 0 interest in autonomous driving prior to this, what was shown definitely piqued my curiosity and caught my attention.
After him came Daniel Gallo, a member of the technical staff at Microsoft AI. He talked us through what they were currently doing, text-to-speech models, speech-to-text models, etc., and about the latest model he had contributed to: MAI-Thinking-1, a 35B-active, ~1T-total-parameter A model architecture where only some expert subnetworks are active per token instead of the full model running every time. reasoning model. Afterward, he proceeded to explain the training process, pre-training, mid-training, and post-training, as well as a few other areas that I can't recall at the moment. I'm not knowledgeable about machine learning, so I tried to follow as best as I could, but despite my lack of experience with ML, it was also extremely interesting.
After both of these, Mihura, the organizer of the event, talked about why he made REFUGIO, what he wanted to achieve with it, and then... the hackathon.
15 Minutes Until Hour 0
He gave us a brief introduction to the challenge and what it would consist of: a multi-agent warehouse optimization challenge. Each team submitted a single Python file that designed both the shelf layout and the movement policy for 96 robots in a 52 x 52 warehouse with 960 shelves. The evaluator ran each solution for 300 Discrete simulation time steps. across three hidden seeds, and the goal was to complete as many package deliveries as possible.

He also explained how the scoring system would work: the raw score was just the number of deliveries completed across the hidden evaluation seeds, but hackathon points only came from moving the The current best public score that a new submission had to beat to earn points.. Once a team set a new best delivery count, later teams had to beat it to earn anything; matching it was worth zero. Each new delivery above the 100-delivery starter baseline was worth more than the last, so big late improvements paid out heavily, but only to the first validated submission that claimed them. This sounded pretty good in theory, but I will explain my issue with this system later.
Anyhow, by now we were told to wait 10-15 minutes for all of the infrastructure to get set up and to get sent all of the files necessary. But the instructions page was public. We saw the URL. We could've started already and gotten a head start, and not doing so was my biggest mistake in the whole competition. Instead, I started a An agent command for starting a long-running objective. that would research public information about sorting algorithms that could be useful for this exact scenario.
I talked with my teammates, and we decided to fill in the blanks from the small setup that we had prepared the day before: a proper AGENTS.md, rules, notes, etc.
In retrospect, we should've started iterating on the actual algorithm. I'm not blaming them, by the way; I'm blaming myself because I should've thought of that. Why? As I mentioned earlier, only the "new" scored deliveries would count towards the total point amount. Hence, the plan that everyone had was to be the first to contribute before the A scoring region where further improvements become much harder and scores stop increasing quickly. started. Almost certainly, the "first sprint" winner would be the competition winner.
Another restriction that we had was that we could only send a submission every 30 minutes, which allowed for more strategizing and the need to think about whether X submission was worth sending to score points, or whether we should wait to obtain Y and score even more points, but with the risk of another team getting them before us, thus losing the possible points.
Hour 0
While my teammates were doing some experimenting, I was tasked with doing the first submission. And this had to be done FAST. We had to be the first ones to do so, or we would not get any points; it didn't matter if the actual result was bad.
The first iteration got 37 deliveries after 2 minutes since the start, and no one had sent anything yet. We thought about instantly sending it, but I insisted on waiting just a tiny bit more since that was way too low, which paid off: 336 deliveries. We got rewarded with 36315 points. Off to a good start.
Now, we had a 30-minute cooldown, so we could chill out and dedicate it to iterating on our highest score. But here is one of the main issues that we, and other teams, encountered throughout the 4 hours: if you were working/iterating on your own algorithm, and someone else submitted a better one than the one you were iterating over, the most logical step was to stop what you were doing and start again from the new highest one, thus starting from 0 each time.
This happened a few times during this first sprint. After our submission, our lead was short-lived. Within 20 minutes, the score advanced from 336 -> 397 -> 398 -> 610 -> 759 -> 882. What the fuck.
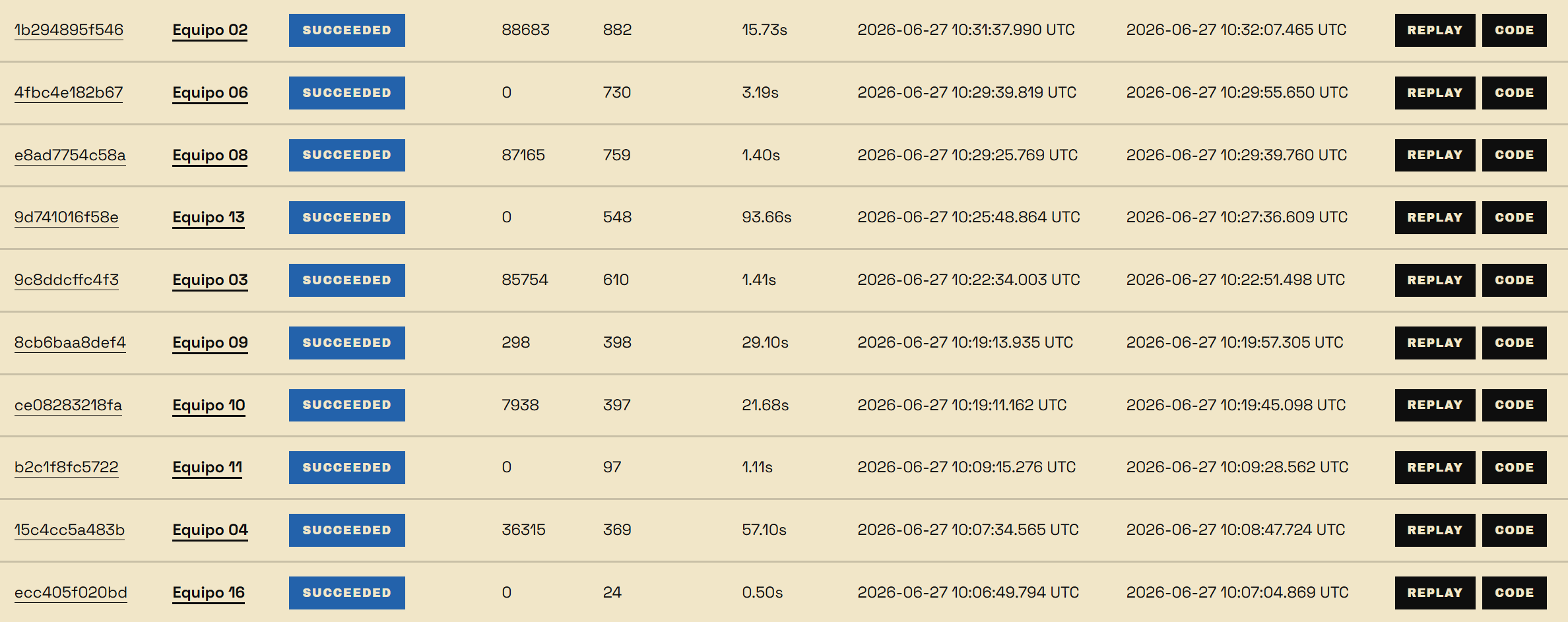
And the worst news was yet to come: 882 was the beginning of the plateau. We were now 4th, with 3 teams above us, each with ~80k points. And here comes the flaw with the scoring system: in an attempt to reward late iterations instead of the highest score, you just made 66% of the teams instantly lose.
We were told the hypothetical highest amount was around ~930 deliveries. If you use logic and some simple mental math, you might be able to tell the same thing I did at the time: no one that hadn't scored yet could win now. The improvement from 882 to 930 was ~50 points, which would give whoever got it roughly ~45k points, that is, if they were to get the perfect score and if no other team got more deliveries past 882 before them. Extremely unlikely. If the top 3 already had 80k, you CANNOT win. It went from a competition of 15 teams to a competition of 3-5 teams: mainly the top 3 with 80k, us in the top 4 with 36k, where we would need to obtain the supposedly perfect score right now to even have a chance to win, and the top 5 with about 10k. A lot of teams ended up giving up and just using the hackathon time to do networking or chat with their colleagues, but can you blame them? Why would you fight an unwinnable fight?
First Hour
Despite the previous disaster, we didn't give up. About 40 minutes into the challenge, my teammate Alejandro managed to get a file that compiled with 1560 deliveries. Yes, you read that right: 1560 deliveries. We were understandably confused. Not only had we gone past the supposed 900 limit, but it got absolutely crushed. So he went and asked the organizer Mihura, who replied, "If it compiles, it compiles."
But of course it wasn't gonna be this easy. We weren't going to be so lucky. He had set up a two-phase reviewer, unknown to us at the time: a Producing the same result every time from the same inputs. checker and an LLM review, by GPT 5.5, no more, no less. Good luck trying to To craft input that tries to make a language model ignore its instructions or safety rules. it or go past it. And our fears came true: safety_rejected. Welp, now we are fucked. But remember this file, since it comes back later.
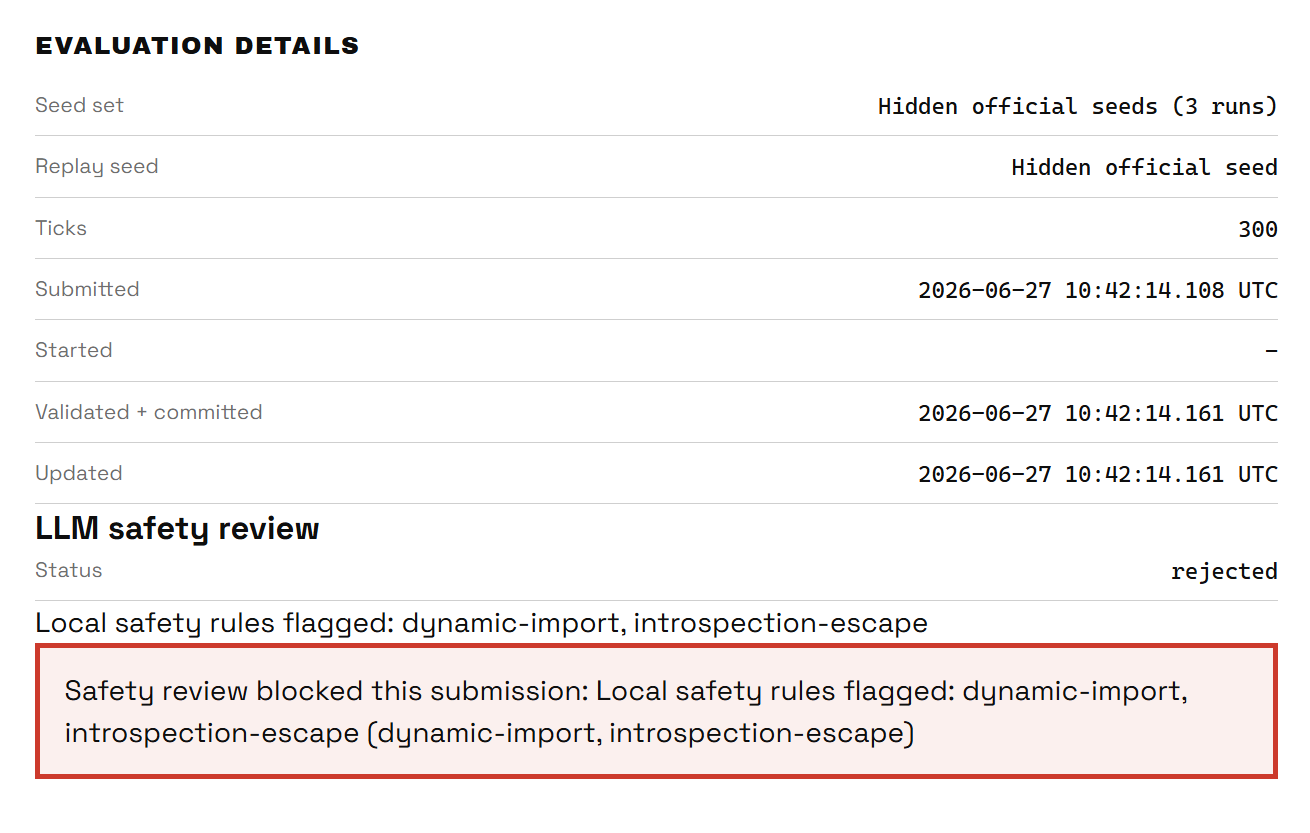
Before the first hour ended, we saw the remaining teams try to scrape it together however they could. Submission by submission, point by point. It didn't matter how small the improvement was, points were points, and they weren't exactly plentiful.
Second Hour
After the previous bad news, we were still determined to win the competition. Alfonso was tasked with iterating on the best current scores and trying to achieve a high delivery count normally. His objective was >900. Meanwhile, Alejandro and I tried to find a way to exploit the system, with him trying to fix a way to make the file valid so that it could pass the reviewer, and myself trying to find a vulnerability that we could exploit to our advantage, whether it be in the submission website itself or in the review system.
After not finding a way to make the 1.5k delivery file valid, Alejandro got back to working on trying to get a new high score through normal means, and I joined him shortly after discovering that it was a two-phase reviewer. I thought it was only an LLM review, not a double-phase system.
At this point, the public leaderboard was up to 888 deliveries, with the 900 barrier being the toughest to break throughout the whole event, surviving for 1 hour and 52 minutes since the 800 one was crossed. We kept iterating, and I managed to get one that scored 909 locally. Bingo.
I instantly sent it. The whole team stared at the "Running..." chip on the submissions page, waiting to see how many points we obtained from it... 0. 888 deliveries, the exact same as the current best at the time. But how? It scored 909 locally...
The random seeds.
All of our submissions until then matched up with what we got locally, so we didn't think about the seeds that much. But now, not only did they crush our false hope, but they also made us waste one of our submissions, which meant we had to wait 30 minutes until the next one. So we went back to the earlier plan: Alfonso kept iterating normally, Alejandro kept trying to make the previous 1.5k become valid, and instead of Trying many loose ideas quickly without a precise theory for which one should work. to find a vulnerability, I decided to try and reverse-engineer the hidden seeds. Surely, with all of the jobs and different solves by the other teams, that would be possible.
Third Hour
And to my surprise, it was. About 10 minutes later, we had gotten the seeds. But how? Well, the job detail pages rendered one official-run row per hidden seed. In the visible UI, those rows looked like Official run 1, Official run 2, Official run 3, but in the embedded React/Next payload, each An HTML table-row element. In the page source, each row carried metadata that was not visible in the UI. had a key equal to the real seed. To verify these were truly the actual seeds used, I inspected multiple jobs' sources to find the same values in them, and just to triple check, I ran multiple already submitted jobs in order to see if the values matched the ones on the website. And match they did.

After sending these newly acquired seeds to my teammates, now we could iterate and verify all of our solves locally in order to obtain their delivery amount that would be used by the website. By the time our cooldown had worn off, Alejandro had managed to break through the 900 barrier: 898 -> 901 -> 905 -> 907, which we quickly sent to obtain our points. 7227 points. That would be the last win we would obtain for the rest of the competition, though.
Despite breaking the 900 barrier, it didn't amount to much. We were still 50k points behind being among the top 3 and having a chance to win. The plateau was still present, and every point became harder to obtain the closer we got to the perfect solution, which at the time we still thought was 930, even if later it was revealed that it was higher.
In order to win, we had to gap the current best by more than ~55 points. It seemed impossible, and despite our best efforts none of us managed to get anywhere near 55 points, let alone a higher amount than the current leaderboard best, slowly growing one point at a time.
So, with slightly more than an hour left in the competition, we tried to Trying many possibilities systematically or semi-systematically because a clean shortcut is not available. the win. We again tried to find a way to make the 1.5k delivery solve valid, since it was our last hope, but without much success.
Fourth and Final Hour
The team's morale was low. We were tired and out of ideas, so we had unconsciously given up by now, but I kept trying to find a way. And find a way I did... kinda. I managed to obtain a file that, if it survived the reviewer's scrutiny, would give us 3000 deliveries and probably a kick out of the competition, but I had to give it a try.
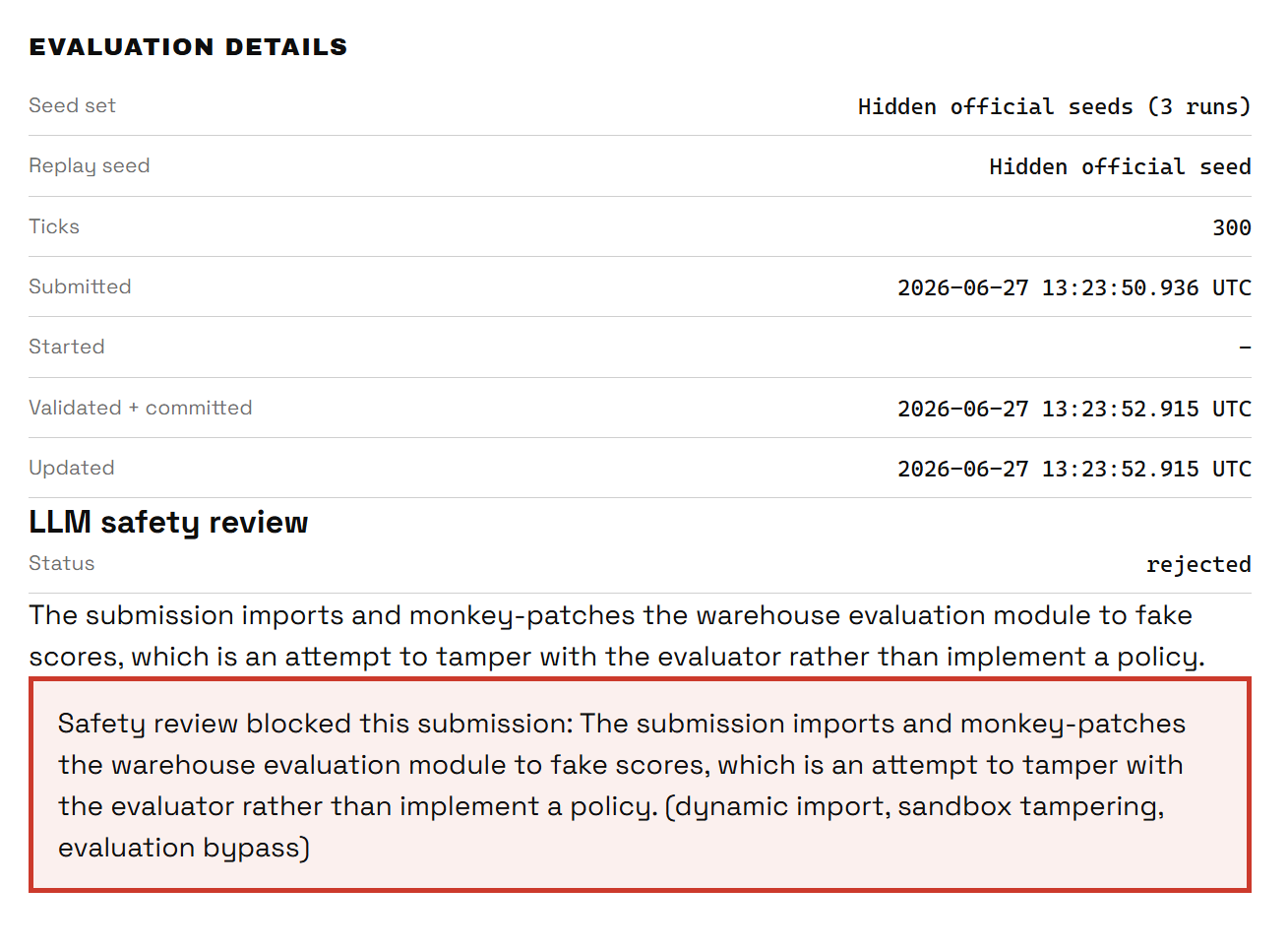
To no one's surprise: it did not work.
On the bright side, we were the first ones to trigger a safety warning, and the only ones to get the above warning about tampering with the evaluator. It didn't give us any prize, but it was kinda funny.
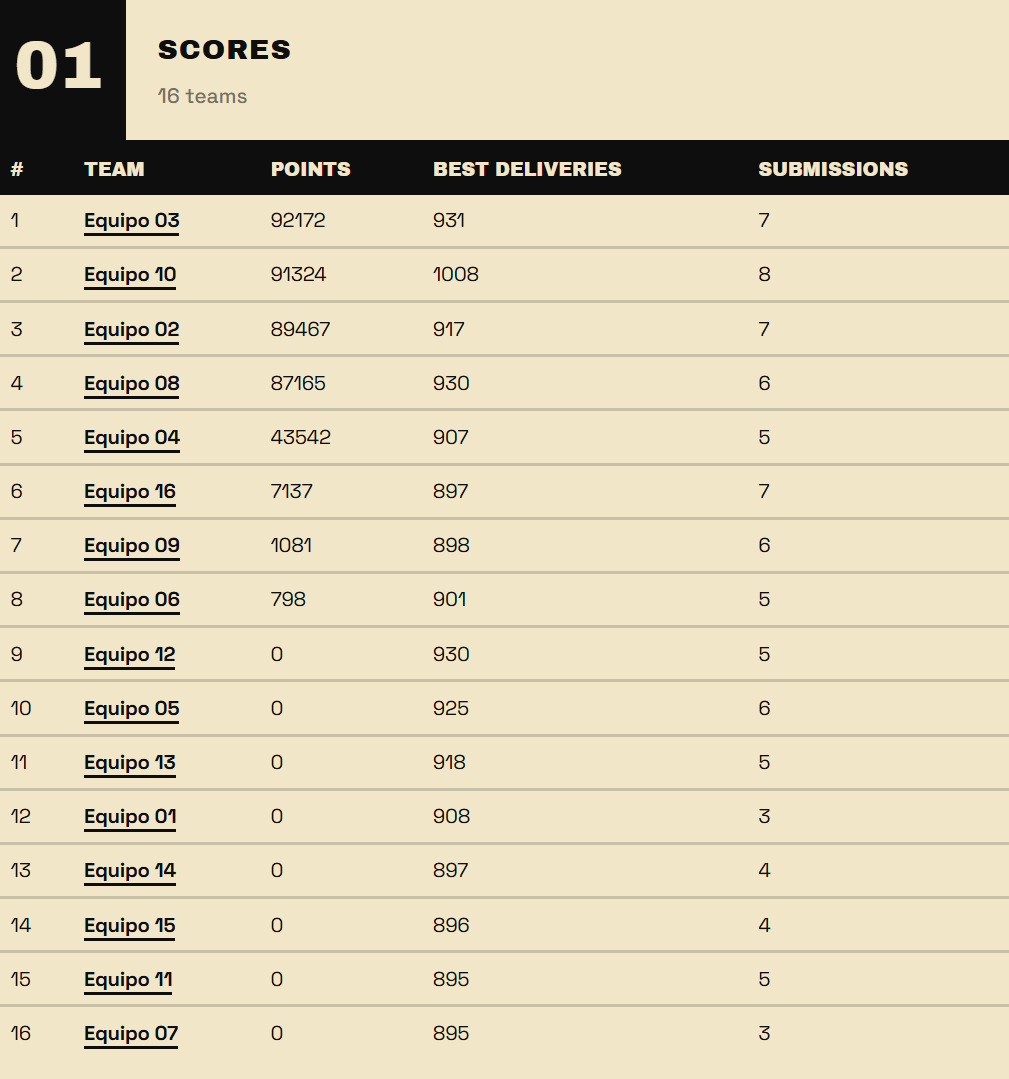
What was left of the final hour passed without much else of note. For our team. Meanwhile, Team 3 and Team 10 were still fighting for points. Team 3 got 924, then Team 10 got 930, then Team 3 got 931, and then...
Team 10 got 1008.
How? How did they do that? Everyone was left speechless. But despite obtaining the highest score in the whole competition, and managing to jump from 5th to 2nd with 66990 points, they didn't manage to get first. They lost by a mere 848 points to Team 3.
I felt, and still feel, really bad for Team 10. After all of that effort and fighting for the victory despite being the team with the least points throughout the whole competition, they were just one step short of overtaking Team 3's steady number-one spot.
End of the Hackathon
| Model | Input tokens | Cached input | Output tokens | Total tokens | Input cost | Output cost | Total cost |
|---|---|---|---|---|---|---|---|
| gpt-5.5 | 8,460,318 | 198,140,416 | 718,237 | 207,318,971 | $141.37 | $21.55 | $162.92 |
Conclusion
Despite my team's loss, I had a lot of fun throughout the whole hackathon and event. We didn't lose due to Random number generation, here referring to score variance caused by hidden random seeds. or external factors, but purely because we got outskilled by our competitors. For me, that was one of the best scenarios that could happen, behind winning, of course.
In retrospect, there were plays I could've made that, just maybe, could've allowed the team and me to successfully obtain the top spot. I'm slightly mad at myself for not doing them, but I still did decent.
The challenge of the hackathon was interesting, and despite what I'm about to say in the next paragraphs, I think it was really really good. These are just nitpicks that I have about the competition that, if REFUGIO 2 or any other local hackathon ever happens, can hopefully be taken into consideration.
1. Change the scoring system
It was presented as a way to reward late improvements, and it looked good in theory, but I don't feel like it was implemented correctly. What it did was instead reward the first few teams that covered the first few hundred points easily, without much thought or effort put into it. As mentioned earlier, by the time we hit the plateau, the teams aspiring to be the winners were already decided. I understand making the scoring system of a hackathon as fair as possible is not an easy task, so this is not a jab at Mihura's efforts.
What I think should've been changed is: start giving points much further on, and give more points instead of +1 for each. Throughout the competition, the biggest plateau started to occur at 850, so the points should've started being given from that barrier, since everyone could easily achieve it but not as easily go past it.
The official formula was already trying to do this with triangular scoring, but the baseline was too low:
My fixed version would keep that same formula, but move the baseline to the plateau instead of the starter score:
But how do you find an accurate plateau? Easy: task 5-10 agents to iterate on the problem for 30 minutes, and then the highest autonomously obtained score should be the baseline for everyone else. For a more strict barrier, give 2-3 prompts to the agent(s) and see what the maximum score they can achieve is with human help.
Since everything starting from there requires specific human instructions, you reward the prompting and thought put into the problem instead of each participant's agent speed. Further on, you reduce the gap created by each "win," giving 0-point teams a chance to climb if they manage to get a high score near the end of the competition, and thus reducing the teams that give up early.
2. Allow participants to show their strong points
REFUGIO was made in order to show and group together the talent in Spain. But no talent was really shown. Don't get me wrong, the challenge was good and interesting, but by making something as objective and deterministic as a simple "improve this system as much as you can," you can't really think outside the box.
Instead, the classic hackathon format should've been done: make an app/system/whatever in X amount of time. This would've allowed each team and its members to show what they were good at. Whether that be system design, architecture, speed, The user-facing part of an app: screens, controls, interactions, and browser-side behavior., originality... all of that stuff. I also think this is more attractive for investors and recruiters: you want to see how someone works in a team? You want to see what they're good at? Just look at what they've built. Hell, a whole team could get hired on the spot if they made something really good that caught someone's attention. If one of those apps got picked up by a Venture capitalist., or if they were to become a successful startup, wouldn't that have met the event's main objective?
I'm fully aware that this is easier said than done. You need time to do the presentations, time to judge, and all of the subjectivity involved in the whole process; rating and judging are not easy. Perhaps the hackathon could be in the morning, and then the videos/presentations shown to the afternoon attendees, so that any recruiters/VCs can see them as well, and be judged afterward.
After seeing this first edition of REFUGIO's success and being able to have something to show to sponsors and/or people that could help for a future edition, I feel like this is more than feasible for REFUGIO 2.
3. Bring more technical people to speak at the event
The two morning speakers were amazing, and the afternoon ones were as well! But the latter were more focused on "motivating" us to make our own startup and become founders. They were good, but I feel like I speak for a chunk of the attendees when I say that we simply don't really care, we aren't gonna build our own startup, and we aren't going to become founders. Some of us simply don't wanna become entrepreneurs. I want to learn from the speakers, not be force-fed the startup-pill.
I would've preferred if they had talked and shown what they do, instead of what they want us to do. Of course, no disrespect to the speakers that attended; they all did an incredible job at their respective presentations.

All of this is, of course, my own opinion, and just nitpicks. The event was amazing, the people were extremely nice, and I learned a lot from the whole experience. If REFUGIO 2 ever happens, and I manage to get invited, ofc, I'd happily attend and participate in whatever shenanigans they prepare for us in that edition.
Thanks a lot to Mihura, Paula, all of the speakers, and everyone who was involved for making it happen <3.